
Fabian Hertwig
Lesezeit: 15 Minuten
Computer Vision: Wie Computer das Sehen lernen
Wir haben 2018 an zwei Computer Vision Challenges teilgenommen und viel gelernt: der Kaggle Plant Seedlings Classification Challenge und dem Data Science Bowl. Kaggle ist wohl die bekannteste Plattform für Data Science und Artificial Intelligence Challenges. Dort finden regelmäßig Wettbewerbe in Kooperation mit Firmen statt. Diese stellen meist sehr gut vorbereitete Daten bereit und die Aufgabe der Teilnehmer…
Wir haben 2018 an zwei Computer Vision Challenges teilgenommen und viel gelernt: der Kaggle Plant Seedlings Classification Challenge und dem Data Science Bowl.
Kaggle ist wohl die bekannteste Plattform für Data Science und Artificial Intelligence Challenges. Dort finden regelmäßig Wettbewerbe in Kooperation mit Firmen statt. Diese stellen meist sehr gut vorbereitete Daten bereit und die Aufgabe der Teilnehmer ist, möglichst gute Vorhersagen auf diesen Daten zu erstellen. Die besten Teilnehmer können Geldpreise gewinnen, aber den meisten Teilnehmern geht es darum, sich mit den besten Data Scientists und Machine Learning Engineers der Welt zu messen. In der Plant Seedlings Challenge war die Aufgabe in Bildern zu erkennen, welche von zwölf verschiedenen Arten an Pflanzkeimligen zu sehen ist.

Aus: A Public Image Database for Benchmark of Plant Seedling Classification Algorithms, freigegeben nach Creative Commons BY-SA Lizenz
Der Datensatz war dabei mit 4000 Bildern für ein Training klein, trotzdem konnte unser Modell mit einer Genauigkeit von 98.3 Prozent die richtige Klasse vorhersagen. Das Training des Modells hat nur wenige Stunden gedauert.
Im Data Science Bowl war die Aufgabe, in mikroskopischen Aufnahmen von Zellmaterial jeden einzelnen Zellkern zu identifizieren. Eine zusätzliche Herausforderung war es, die Zellkerne trotz verschiedener Auflösungen der Bilder und Arten von Einfärbungen des Zellmaterials zu erkennen.
In beiden Challenges haben wir uns einen Platz unter den besten 10 Prozent der Teilnehmer gesichert. An den Challenges lassen sich die Fortschritte von Computer Vision gut zeigen.
Zunächst gibt es eine eher einfache Aufgabe: bestimmen, was auf dem Bild zu sehen ist. Darum geht es in diesem Blogbeitrag.
Computer erkennen Objekte besser als Menschen
Seit 2012 gab es im Bereich Computer Vision jedes Jahr unglaubliche Fortschritte. Diese wurden durch Deep Learning und die Weiterentwicklungen der Deep-Learning-Modelle und -Methoden vorangetrieben. Als Benchmark messen sich Forscher meistens in der Large Scale Image Recognition Challenge mit dem ImageNet Datensatz. Dieser Datensatz wurde von Forschern erstellt und besteht aus über einer Million von Menschen gelabelten Fotos. Die Modelle müssen erkennen, welches von insgesamt 1000 möglichen Objekten sich in einem Bild befindet. Zum Training der Modelle stehen 1,2 Millionen Bilder zur Verfügung. Wie gut die Modelle die Objekte erkennen, wird mit 100.000 Bildern getestet. Dabei sind die Unterschiede der Klassen teilweise sehr subtil. Zum Beispiel sind mehr als 120 verschiedene Hunderassen in dem Datensatz vertreten. Die Modelle müssen nicht nur erkennen, dass sich ein Hund in dem Bild befindet, sondern welche Hunderasse es genau ist. Ähnlich ist es bei Vögeln, Schlangen und Affen.
Den ImageNet-Datensatz kann man sich hier ansehen.
Mensch vs. Modell
2014 hat sich Andrej Karpathy die Aufgabe gestellt, die subtilen Unterschieden zwischen den Klassen selbst zu lernen und die Objekte in 1500 Bildern des Testsets manuell zu klassifizieren. Während des Trainings konnte er die Bilder des Trainingsdatensatz durchsuchen und sich Bilder als Vergleich anschauen. Pro Bild brauchte er zirka eine Minute, um die Klasse festzustellen. Er erreichte damit eine Fehlerrate von 5.1 Prozent, zu der Zeit noch besser als die besten Deep Learning Modelle. Doch diese haben ihn schon im folgenden Jahr überholt.
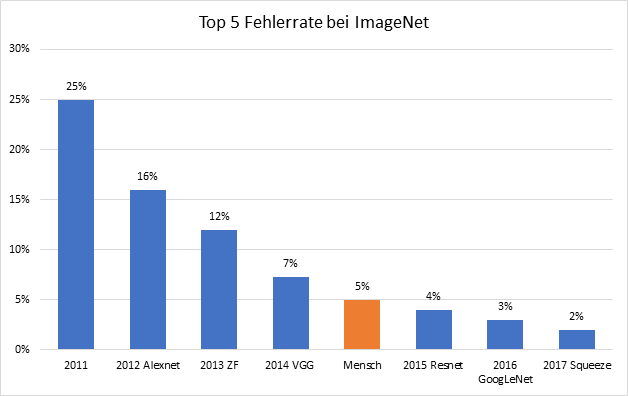
Heute unterbieten Deep-Learning-Architekturen den Menschen bei den Fehlerraten. Sie schlagen die menschliche Performance nicht nur bei dem Erkennen von Objekten im ImageNet Datensatz, sondern auch wenn es darum geht Hautkrebs zu erkennen, Lippen zu lesen oder Gesichter zu unterscheiden. Doch die Modelle sind nicht immer besser: Sobald Bilder verschwommen, verzerrt oder mit Bildfehlern versehen sind, fällt die Performance der Modelle stark ab, während die der Menschen gleich bleibt. Dadurch lässt sich schließen, dass Menschen und Deep Learning Modelle Gegenstände auf sehr unterschiedliche Art erkennen. Trotzdem ist die Performance der heutigen Computer-Vision-Modelle erstaunlich. In den nächsten Absätzen möchte ich beschreiben wie diese Modelle funktionieren.
Wie Deep Learning Modelle sehen
Architektur
Neuronale Netzwerke sind in Schichten aufgebaut. Die Daten fließen in die erste Schicht ein und werden dort verarbeitet; die Ergebnisse werden an die nächste Schicht weitergegeben. An der letzten Schicht gibt das Netzwerk seine Prädiktion aus. Im Fall der Plant Seedlings Classification Challenge ist die Prädiktion, zu welcher der 12 vorgegebenen Klassen ein Bild gehört.
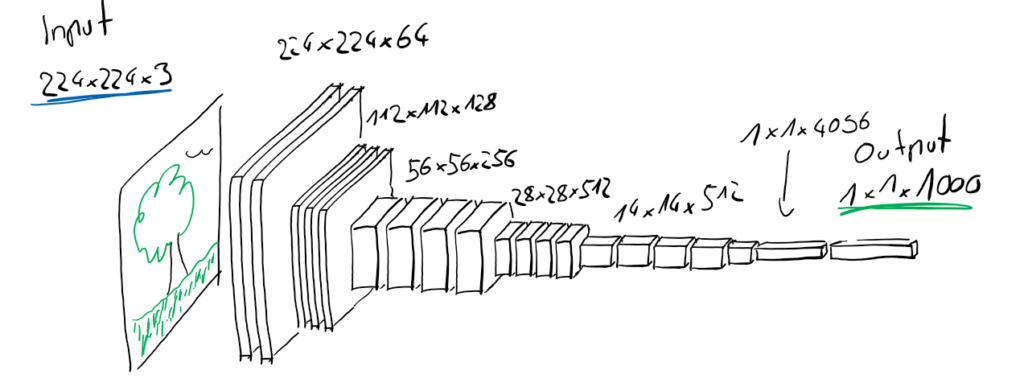
2014 gewann das VGG Netz die Large Scale Image Classification Competition. Im Bild sieht man vereinfacht, wie es arbeitet:
(c) Fabian Hertwig
Auf der linken Seite wird ein Bild mit einer Höhe und Breite von 224 Pixeln und 3 Dimensionen für den Roten, Grünen und Blauen Kanal eingegeben. Auf der rechten Seite werden 1000 einzelne Werte ausgegeben. Das ist die Einschätzung des Netzwerkes für jede der 1000 Objekte, ob diese auf dem Bild zu sehen sind. Dazwischen wird die Eingabe so weiterverarbeitet, dass die Höhe und Breite kleiner wird, aber immer mehr Dimensionen entstehen. So sind es in der ersten Schicht immer noch 224 Pixel Breite und Höhe, aber 64 Dimensionen. In den nächsten Schichten wird die Größe halbiert auf 112 Pixel, aber die Dimension auf 128 verdoppelt.
Convolutions
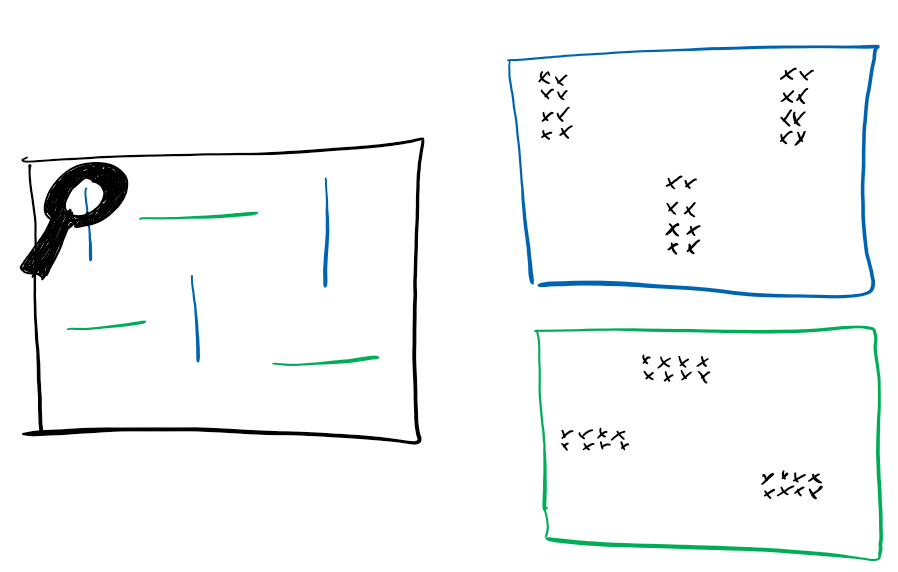
Jede dieser zusätzlichen Dimensionen beschreibt, wo sich ein bestimmtes Merkmal in dem Bild befindet. Ein Merkmal kann so einfach sein wie eine Kante, aber auch so komplex wie ein Auge oder eine Autofelge. Das Merkmal wird gefunden, indem ein Filter über das Bild geschoben wird, der nach genau diesem Merkmal sucht.
(c) Fabian Hertwig
Man könnte sich das so vorstellen: Jemand durchsucht das Bild mit einer Lupe und beginnt oben links. Gesucht wird ein spezielles Merkmal, in unserem Beispiel die blau dargestellte vertikale Kante. Wenn er eine findet, macht er auf einem extra Blatt oben links ein Kreuz. Dann schiebt er die Lupe 1cm weiter und macht wieder ein Kreuz auf dem gleichen Blatt, wenn er wieder eine Kante findet. So macht er weiter bis er das ganze Bild abgesucht hat. Dann beginnt er von vorne, sucht aber nach einem anderen Merkmal, zum Beispiel nach einer horizontalen Kante – hier in grün. Seine Funde notiert er wieder als Kreuze, aber auf einem neuen Blatt Papier. Dies macht er für viele verschiedene Merkmale. Jedes dieser Papiere mit den Kreuzen entspricht dann einer der oben beschriebenen Dimensionen. In den nächsten Schritten werden diese Blätter quasi übereinandergelegt und ergeben somit ein neues Bild, in welchem wieder nach Merkmalen gesucht wird. Zum Beispiel könnte man nun nach Ecken suchen, welche aus den zuvor gefundenen Kanten bestehen. So geht es weiter, bis die Bilder nur noch eine sehr komprimierte Repräsentation der Merkmale darstellen. Die Featuremaps im VGG Netz sind am Ende nur noch 14 Pixel Breit und Hoch, allerdings werden in diesen 512 verschiedene Merkmale repräsentiert.
Das Schieben eines Filters über das Bild nennt man Convolution – daher der Name der Convolutional Neural Networks.
Das folgende Bild zeigt eine Convolution. Die Eingabe ist blau und der Filter ist grau. Aus diesen wird eine sogenannte Featuremap berechnet, welche in grün dargestellt wird. Diese Featuremap gibt an, wo im eingebebenen Bild das Feature gefunden wurde. Im Beispiel mit der Lupe wäre die Featuremap eines der Blätter mit den Kreuzen.
Vincent Dumoulin, Francesco Visin – A guide to convolution arithmetic for deep learning (BibTeX), Lizenz: https://github.com/vdumoulin/conv_arithmetic/blob/master/LICENSE
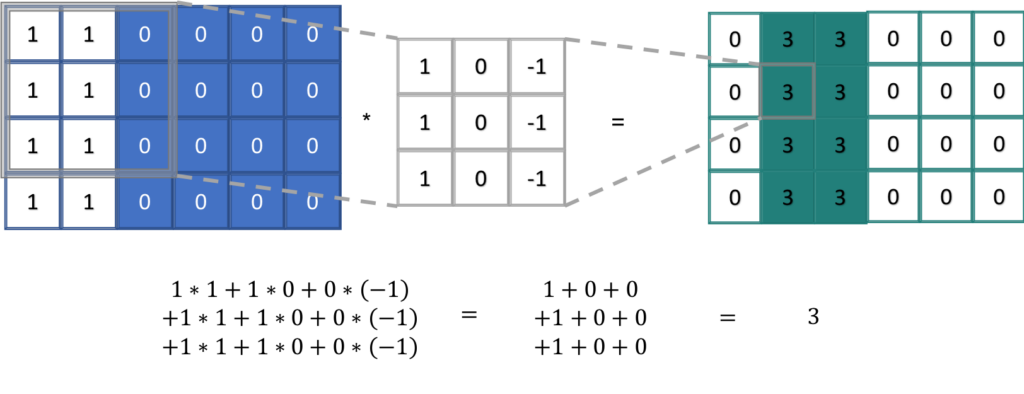
In den Convolutional Neural Networks wird die Featuremap berechnet, indem der Filter mit einem entsprechenden Teilbereich multipliziert und das Ergebnis summiert wird. (Es wird das Skalarprodukt aus einem Teil des Bildes und dem Filter berechnet.) In folgendem Beispiel ist in Blau wieder das Eingabebild. Dies hat eine vertikale Kante. Helle Pixel haben den Wert 1 und dunkle den Wert 0. In grau ist der Filter zu sehen. Der Filter erkennt vertikale Kanten. Wird er mit einem Bildbereich mit einer vertikalen Kante multipliziert, ergibt das einen höheren Wert als für einen Bildbereich ohne vertikale Kante. Die Featuremap hat dadurch nur dort hohe Werte, wo in der entsprechenden Eingabe die Kante zu sehen ist.
Wie sehen Filter aus
In den nächsten Schichten des neuronalen Netzwerkes werden erneut Filter mit den Featuremaps der vorherigen Schichten multipliziert. Somit entstehen Features von Features. Dieses Konzept macht Convolutional Neural Networks so mächtig. In den unteren Schichten wird nach einfachen Merkmalen wie Kanten und Farbverläufen gesucht. In den folgenden Schichten werden diese zusammengesetzt zu komplexeren Features wie Kanten, Kurven und einfachen Mustern, etwa Bienenwaben oder Text. In weiter fortgeschrittenen Schichten werden bereits Objekte erkannt, wie zum Beispiel Autofelgen oder Augen. Zuletzt kann das Netz das Objekt auf dem Bild erkennen, indem es einzelne Merkmale zusammensetzt. Sind zum Beispiel zwei haarige, spitze Ohren, eine Stupsnase und Schnurrhaare zu sehen, so handelt es sich – wahrscheinlich – um eine Katze.
Zeiler und Fergus zeigen in ihrem Paper ein Bild, in dem man die Filter eines Convolutional Neural Networks sehen kann. Es wurde auf dem ImageNet Datensatz trainiert (pfd) In größtenteils grau sind verschiedene Filter zu sehen. Daneben befinden sich Ausschnitte aus Bildern, bei welchen diese Filter besonders hohe Werte ausgeben.
Das folgende Bild zeigt ein einfaches Convolutional Neural Network mit 10 Filtern. Unter CONV kann man jeweils die entstehende Featuremap sehen. Bei RELU sieht man die gleiche Featuremap, nur wurden negative Werte auf 0 gesetzt. Unter POOL wird die Größe der Featuremap verkleinert. Unter FC sieht man die Konfidenz des Netzwerkes, zu welcher Klasse das Bild gehört. Man kann erkennen, dass die Featuremaps für uns Menschen in den tieferen Schichten keinen großen Sinn ergeben. Dort sind nur noch einzelne helle Pixel zu sehen. Die Modelle können damit allerdings sehr gute Vorhersagen treffen. Eine Live-Version dieses Modells kann man unter stanford.edu sehen.
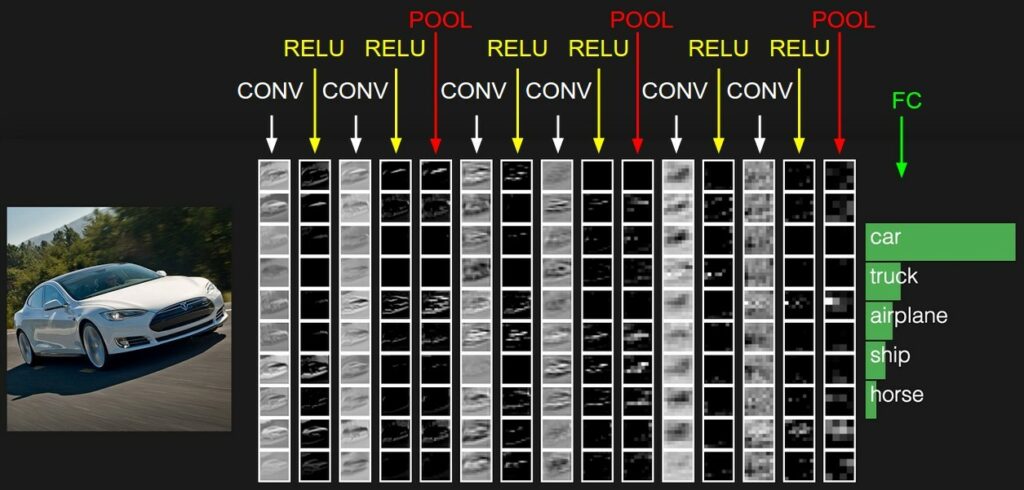
Lizenz https://github.com/cs231n/cs231n.github.io/blob/master/LICENSE
Wie entstehen die Filter
Anfangs sind die Filtermatrizen noch mit zufälligen Werten gefüllt. Im Training lernt das Modell, wie diese Filter aussehen müssen, damit es möglichst fehlerfrei das richtige Objekt auf dem Bild erkennt. Dazu wird dem Modell ein Bild gezeigt, welches es klassifizieren soll. Dann wird der Fehler des Modells an der Ausgabeseite gemessen. Damit wird rückwärts Schicht für Schicht berechnet, wie die Filter geändert werden müssen, damit der Fehler kleiner wird. Diese Änderung der Filter wird mit vielen verschiedenen Bildern und in vielen kleinen Schritten durchgeführt, bis das Modell keine Verbesserung mehr zeigt.
Ein Modell trainieren
Ein Modell von Grund auf zu trainieren braucht Zeit. Zum Beispiel dauert das Training von modernen Modellen auf dem ImageNet Datensatz mit einer einzelnen Hochleistungs-GPU um die zwei Wochen. Zudem braucht es sehr viele Trainingsdaten. Bei ImageNet stehen 1,2 Millionen Beispielbilder zum Training bereit.
Bei der Plantseedlings Challenge gab es nur 4000 Bilder zum Trainieren; trotzdem war es uns möglich, ein Modell innerhalb weniger Stunden sehr genau zu trainieren. Die Methode, die das ermöglicht ist das Transferlearning.
Transferlearning
Beim Transferlearning nutzt man aus, dass die Filter von bereits trainierten Netzen in den unteren Schichten nach sehr einfachen Merkmalen suchen, wie Geraden, Ecken oder Kreise. So nimmt man ein bereits trainiertes Modell für z.B. den ImageNet Datensatz und ersetzt die obersten Schichten durch neue und nicht-trainierte, aber in der Form auf die neue Aufgabe angepasste Schichten. Die unteren Schichten behält man und sie werden zunächst eingefroren, so dass sie beim Training nicht verändert werden können. Somit muss das Modell beim Training die neuen oberen Schichten so anpassen, dass es mit den Featuremaps aus den unteren Schichten der vorherigen Aufgabe gute Ergebnisse liefert. Nach ein paar Trainingsschritten wird dem Modell auch erlaubt, die Filter der unteren Schichten zu ändern. So könnte das Modell zum Beispiel einen Filter, der im ImageNet Datensatz nach Felgen sucht, so abändern, dass der Filter nun nach einer bestimmten Form eines Blattes sucht.
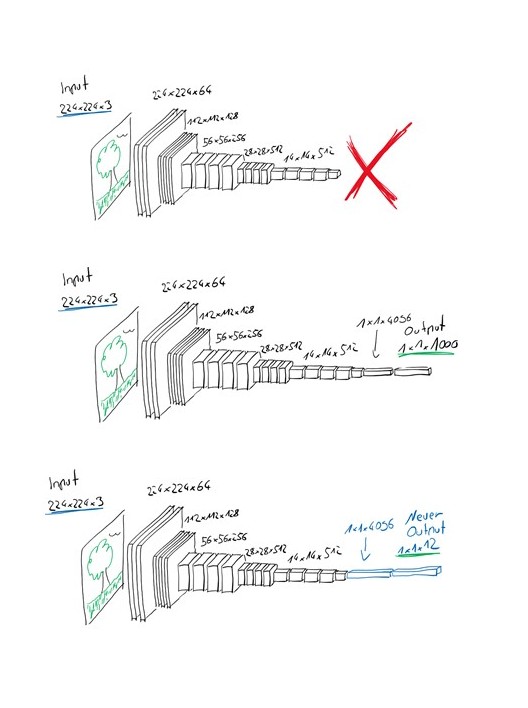
Das Modell hat quasi mit dem ImageNet Datensatz gelernt, aus welchen Merkmalen Objekte auf Fotos bestehen und kann nun diese Merkmale verwenden, um zu lernen wie ganz andere Objekte erkannt werden. Das funktioniert sogar noch, wenn die neuen Bilder kaum eine Ähnlichkeit zu dem ImageNet Datensatz haben, wie zum Beispiel bei Satellitenbildern oder mikroskopischen Aufnahmen von Zellmaterial.
Trainingszeit verkürzen
Transferlearning ist mittlerweile die Standard-Methode bei Computer-Vision-Problemen. Es reduziert sowohl die benötigte Trainingszeit als auch die benötigte Datenmenge. Trotzdem liefern die Modelle sehr gute Ergebnisse – etwa unsere 98,3 Prozent Genauigkeit bei der Plant Seedlings Challenge.
In diesem Blog habe ich gezeigt, wie ein Modell herausfindet, was auf einem Bild zu sehen ist. In der nächsten Stufe finden wir heraus, wo im Bild welches Objekt ist. Diesen Teil werde ich in meinem nächsten Blogbeitrag beschreiben.
Über den Autor
Fabian Hertwig
Data & AI
Fabian arbeitet seit 2016 bei MaibornWolff und leitet, entwickelt und berät in Machine Learning Projekten. Fabian interessiert sich dafür, wie modernste Technologien für einen positiven Beitrag eingesetzt werden können. Getrieben von dieser Neugier kam er so zum Informatikstudium und spezialisierte sich auf Deep Learning. Python und Pytorch sind seine lieblings Programmiersprache und Technologie. Auch privat ist Fabian neugierig und probiert viele verschiedene Sportarten aus, nur dem Mountainbiken ist er über viele Jahre treu geblieben.
Twitter: @FabianHertwig, LinkedIn: https://www.linkedin.com/in/fabian-hertwig, Website: https://fabianhertwig.com
Weiterlesen
-
Techblog
DevOps in der Praxis: Wie Sie Zusammenarbeit neu definieren
DevOps verbindet Entwicklung und Betrieb und ermöglicht es, Software schneller, effizienter und stabiler bereitzustellen. Erfahren Sie, wie der DevOps-Lebenszyklus funktioniert, welche Tools und Methoden Sie einsetzen können und welche Vorteile dieser Ansatz für Ihre Teams und Prozesse bietet.
-
Techblog
Cloud Architekturen verstehen und optimal nutzen
Die richtige Cloud-Architektur ist der Schlüssel, um IT-Ressourcen effizient zu nutzen, Kosten zu senken und flexibel auf Veränderungen zu reagieren. Aber was genau macht eigentlich eine erfolgreiche Cloud-Architektur aus?

