Lesezeit: 5 Minuten
Aufbau einer wiederverwendbaren Testautomatisierungs-Architektur
Zu Beginn eines Projektes ist eine der Aufgaben der Aufbau einer Testautomatisierungsarchitektur. Von Vorteil ist es, wenn ein Starterprojekt existiert, auf dem aufgebaut werden kann. Aus diesem Grund sollte eine Automatisierungsarchitektur so aufgebaut werden, dass sie unter Umständen in anderen Projekten verwendet werden kann. Zusätzlich sollte ein Framework so aufgebaut werden, dass auf Änderungen im System…

Zu Beginn eines Projektes ist eine der Aufgaben der Aufbau einer Testautomatisierungsarchitektur. Von Vorteil ist es, wenn ein Starterprojekt existiert, auf dem aufgebaut werden kann. Aus diesem Grund sollte eine Automatisierungsarchitektur so aufgebaut werden, dass sie unter Umständen in anderen Projekten verwendet werden kann. Zusätzlich sollte ein Framework so aufgebaut werden, dass auf Änderungen im System Under Test schnell reagiert werden kann.
In diesem Beitrag möchte ich einen Aufbau zeigen, mit dem dies möglich ist. Dabei ist das Framework als Ergänzung zu meinem früheren Blogbeitrag (Ein Architekturpattern für die Testautomatisierung) zu sehen.
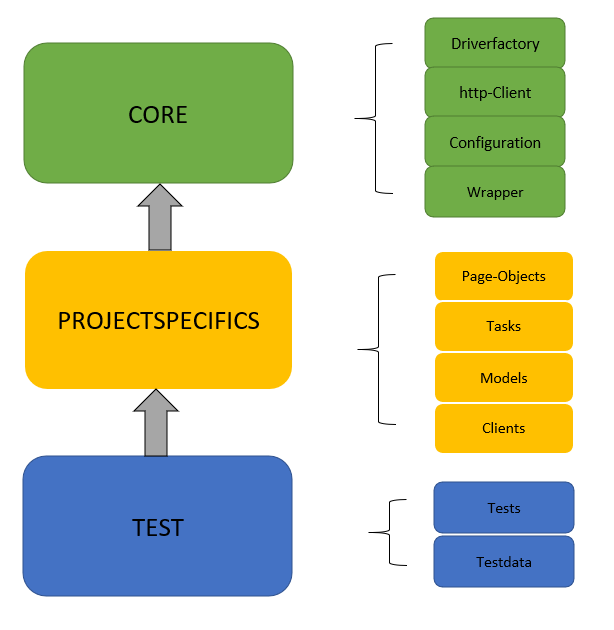
Die Darstellung zeigt den Aufbau eines wiederverwendbaren Codes. Dieser unterteilt sich in drei Abschnitte: Core, Projektspezifisches und Test.
Core
Der Core beinhaltet projektunabhängigen Code. Dieser Code kann in jedem neuen Projekt verwendet werden. Ggf. müssen weitere Frameworks integriert oder andere – nicht benötigte – entfernt werden.
In dem Core-Code sind unterschiedliche Frameworks inklusive verschiedener Wrapper eingebaut, die für Automatisierungen benötigt werden. Mögliche Beispiele sind:
- eine Driverfactory, welche einen Browser (Selenium) oder eine Mobileapp (Appium) startet. Zudem zusätzliche Wrapper, die weitere Möglichkeiten bieten. Beispielsweise könnte ein Element-Objekt ein Selenium-Webdriver-Element wrappen und um eine Möglichkeit erweitern, den übergebenen Locator auszugeben;
- einen http- oder Datenbankclient, um entsprechende Daten zu erstellen, abzufragen bzw. um die Schnittstellen zu testen;
- Konfigurationsmöglichkeiten, so dass bspw. Endpunkte über eine Json oder Yaml definiert werden können;
Projektspezifika
In diesem Codeabschnitt werden die projektspezifischen Inhalte erstellt:
- Im Fall einer Frontendautomatisierung werden hier die Page-Objects definiert;
- Tasks und Actions, welche die technische und fachliche Logik definieren, werden erstellt (siehe https://www.maibornwolff.de/blog/ein-architekturpattern-fuer-die-testautomatisierung);
- Models, welche die Datenobjekte darstellen, werden definiert. Hier empfiehlt es sich die Objekte aus dem Produktivcode zu übernehmen;
- Clients werden definiert, um damit beispielsweise auf http-Schnittstellen zugreifen zu können.
Test
In diesem Teil wird kein produktiver Code mehr erstellt. Stattdessen befinden sich darin:
- Die Tests, welche die Tasks nacheinander ausführen, und
- Testdaten, die in den Tests verwendet werden.
Jedes dieser Teilprojekte hat eine Abhängigkeit auf das darüberliegende Teilprojekt:
- Das Testprojekt verwendet Code aus dem projektspezifischen Teilprojekt, um auf die Tasks zuzugreifen.
- Das projektspezifische Teilprojekt greift auf den Core zu. Weitere funktionale Dependencies werden so gut wie nicht verwendet, da benötigte Funktionalitäten als Wrapper durch das Core-Teilprojekt zur Verfügung stehen. Jedoch wird in diesem Abschnitt das Testframwork importiert.
- Das Core-Teilprojekt beinhaltet die meisten externen Dependencies (Selenium, Appium, Rest-Client, …) und wrappt diese in eigene Klassen. Dadurch muss das projektspezifische Teilprojekt nicht angepasst werden, wenn sich eine Dependency ändert.
Anpassbar je nach Sprache
Die Architektur lässt sich unabhängig von der verwendeten Sprache und den verwendeten Frameworks verwenden. Werden die Projektspezifika aus dem Testprojekt entfernt, so bleibt am Ende das Core-Teilprojekt, sowie die Strukturen der beiden anderen Teilprojekte. Aus diesen wurden alle projektspezifischen Klassen entfernt.
Diese Architektur kann beispielsweise umgesetzt werden:
- Java/ Kotlin: als core-Projekt wird https://github.com/munichbughunter/SevenFacette verwendet. Dieses beinhaltet viele notwendige Automatisierungsframeworks. Der gesamte projektspezifische Teilprojekt wird im src/java-Part definiert. Die Tests entsprechend im Part test/java.
- Javascript: hier werden verschiedene Ordner pro Abschnitt erstellt. Lediglich die Unterscheidung zwischen den Abschnitten bezüglich der Dependencies ist hier nicht möglich, allerdings deren Einsatz.
- C# bietet die klarste Unterteilung. Durch das Kreieren einer Solution mit mehreren Projekten, angepasst an die drei genannten Abschnitte, lässt sich hier eine klare Aufteilung erzeugen. Als Core-Framework bietet sich hier etwa https://github.com/MaibornWolff/musketeer an.
Auch lassen sich unterschiedliche Testframeworks anwenden:
- Wird ein Unit-Testing-Framework wie TestNg, nUnit oder ähnliches verwendet, so werden die Tasks in dem projektspezifischen Part definiert und im Testteilprojekt als Methoden angewendet.
- Wird ein BDD-Framework wie Cucumber verwendet, so werden das Testteilprojekt durch Feature-Files ersetzt und die Steps entsprechen den Tasks im projektspezifischen Abschnitt definiert.
Leichterer Start in Projekt
Dieser projektunabhängige Code kann in einem eigenen Repository abgelegt und dokumentiert werden. Dadurch können KollegInnen, die ein neues Projekt starten, diesen Code direkt verwenden. Wichtig ist, dass in dann Aktualisierungen von Dependencies oder sonstige Ergänzungen/ Änderungen direkt wieder in das Repository zurückgespielt werden. Dadurch stehen diese Änderungen allen anderen zur Verfügung und das Projekt bleibt zudem aktuell.
Über den Autor
Weiterlesen
-
Techblog
DevOps in der Praxis: Wie Sie Zusammenarbeit neu definieren
DevOps verbindet Entwicklung und Betrieb und ermöglicht es, Software schneller, effizienter und stabiler bereitzustellen. Erfahren Sie, wie der DevOps-Lebenszyklus funktioniert, welche Tools und Methoden Sie einsetzen können und welche Vorteile dieser Ansatz für Ihre Teams und Prozesse bietet.
-
Techblog
Cloud Architekturen verstehen und optimal nutzen
Die richtige Cloud-Architektur ist der Schlüssel, um IT-Ressourcen effizient zu nutzen, Kosten zu senken und flexibel auf Veränderungen zu reagieren. Aber was genau macht eigentlich eine erfolgreiche Cloud-Architektur aus?

