
Richard Gross
Lesezeit: 19 Minuten
Connascence: Regeln für gutes Software-Design
Trotz unzähliger guter Bücher zum Thema ist das Design von Software im Tagesgeschäft nach wie vor eher Kunst als Wissenschaft. Da Software von Teams entwickelt wird und (Kunst-)Geschmack sich selten gleicht, ist das eine sehr unglückliche Situation. Oft sieht die “Grüne-Wiese-Software” nach einem Jahr dann auch aus, als ob Picasso, George Lucas und Mozart gemeinsam einen japanischen Garten angelegt hätten. Pro…
Trotz unzähliger guter Bücher zum Thema ist das Design von Software im Tagesgeschäft nach wie vor eher Kunst als Wissenschaft. Da Software von Teams entwickelt wird und (Kunst-)Geschmack sich selten gleicht, ist das eine sehr unglückliche Situation. Oft sieht die “Grüne-Wiese-Software” nach einem Jahr dann auch aus, als ob Picasso, George Lucas und Mozart gemeinsam einen japanischen Garten angelegt hätten. Pro Team gibt es vermutlich Regeln, in welche Schicht meine neu geschriebenen zehn Zeilen Code gehören. Aber gehören diese Zeilen überhaupt zusammen und sind diese zehn bespielhaften Zeilen jetzt guter oder schlechter Code? Wo ist die gemeinsame Theorie und gemeinsame Sprache, mit der wir im Tagesgeschäft unterscheiden können, ob wir bei Code linksrum, rechtsrum oder lieber gar nicht gehen?
Erfahrung kann es nicht sein, denn diese ist bekanntlich verschieden und ebensowenig übertragbar. Design Patterns sind es eben so wenig, weil sie eine Lösung für nur einen einzigen Kontext beschreiben und bei unbekannten Situationen nicht helfen. Bleiben Begriffe wie tight oder loose coupling. Diese werden zwar gerne benutzt, aber was denn jetzt tight coupling bedeutet, liegt auch eher im Auge des Betrachters; wie man von tight zu loose kommt ist nebulös, und ob es etwas zwischen tight und loose gibt, bleibt unklar.
Betrachten wir also beispielhaft folgenden Codeausschnitt eines Videofilmverleihs (video store). Was sind die Kriterien, die diesen Code zu gutem oder schlechtem machen?

Martin Fowler zeigt den obigen Code in einem Blog Post und nähert sich dieser Frage über so genannte Code Smells.
“A code smell is a hint that something has gone wrong somewhere in your code. Use the smell to track down the problem. […] Highly experienced and knowledgeable developers have a “feel” for good design. Having reached a state of “UnconsciousCompetence,” where they routinely practice good design without thinking about it too much, they find that they can look at a design or the code and immediately get a “feel” for its quality, without getting bogged down in extensive “logically detailed arguments”. […] If something smells, it definitely needs to be checked out, but it may not actually need fixing or might have to just be tolerated.”
— C2 Wiki
Wenn wir erfahren sind, haben wir also ein Gefühl für guten und schlechten Code. Wenn wir es nicht sind, haben wir dann also keine Ahnung, wie Code zu designen ist? Das ist ziemlich unbefriedigend.
Erfahrene Entwickler haben Erklärungen für bekannte Smells niedergeschrieben, in eine Taxonomie eingeordnet und sie damit zu einer Art Nachschlagebuch für potenziell schlechtes Softwaredesign gemacht.
In dieser Hinsicht sind Smells also sehr hilfreich. Ich greife selbst gerne auf diese Sammlung von Erfahrung zurück, um ein Design im Nachhinein zu bewerten. Um Design wirklich zu verstehen, ein Design gegen ein anderes abzuwägen oder ein komplett neues Design zu entwerfen, ist das aber nicht genug.
Wir sind also wieder bei unserer Anfangsfrage: Was sind die Kriterien für guten und schlechten Code? Auf der Suche nach einer Antwort bin ich durch Zufall über Connascence gestolpert.
Elemente von Connascence
Connascene ist eine Software-Qualitätsmetrik und Taxonomie der Verbindungen, die in unserem Code entstehen. Sie wurde 1992 von Meilir Page-Jones in einem Paper beschrieben und wurde später Teil seines ersten Buches und sie tauchen im Nachfolger auf. Vor ein paar Jahren hat Jim Weirich sie wieder aufgegriffen und bezeichnete sie auch scherzhaft als die Grand Unifying Theory of Software Design.
Durchaus große Vorschusslorbeeren also, doch was verbirgt sich hinter diesem seltsamen Begriff? Nascency heißt übersetzt Entstehung. Der Präfix Co stammt aus dem lateinischen und bedeutet gemeinsam oder zusammen. Connascence scheint sich also um die gemeinsame Entstehung von Code zu drehen. Die offizielle Definition bestätigt das auch:
“2 elements A,B are connascent if there is at least 1 possible change to A that requires a change to B in order to maintain overall correctness” — Meilir Page-Jones
Das klingt auf den ersten Blick ähnlich wie das eingangs erwähnte Coupling. Tatsächlich ist für Meilir Page-Jones Connascence die Generalisierung von Coupling und Cohesion. Anders als die zuletzt genannten ist Connascence nicht nebulös; mit Connascence können wir ein Design bewerten, vergleichen und gleich auch Refactoring-Vorschläge ableiten. Wir werden sehen, dass zwischen Elementen Connascence entstehen kann, auch wenn sie nie miteinander kommunizieren.
Statische Formen von Connascence
Connascence of Name (CoN)
CoN ist die schwächste Form und gleichzeitig aber auch die Connascence mit der größten Vielseitigkeit, weil Namen in Software in sehr vielen Varianten auftreten.
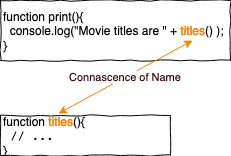
In unserem Beispiel hat die Funktion print() eine Abhängigkeit auf die Funktion titles(). Wenn ich titles() umbenenne, muss ich den Aufruf in print() auch anpassen, sonst wäre mein Programm nicht mehr korrekt.
Machen wir unser Beispiel doch etwas komplizierter und fügen eine Datenbank ein.
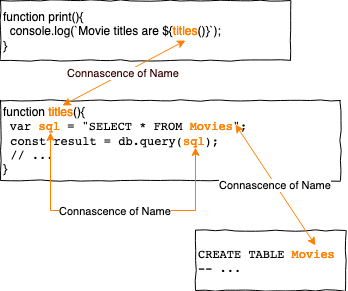
Jetzt erhöhen Variablen und auch “harmlose” Strings die CoN. Die Variablen result und db besitzen auch eine CoN auf ein anderes Element. Dieses haben wir allerdings nicht in unser Beispiel eingezeichnet.
Connascence of Type (CoT)
CoT bedeutet, dass sich zwei Elemente einig sein müssen über den Typ.
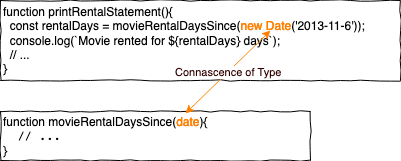
movieRentalDaysSince(new Date('2013-11-6')) ist korrekt, movieRentalDaysSince(2013, 11, 6) erzeugt einen SyntaxError.
In statisch typisierten Sprachen können wir viele dieser Fehler bereits früh erkennen, in dynamisch typisierten Sprachen benötigen wir eine gute Testabdeckung. In allen Sprachen bleibt die CoT.
Connascence of Convention (CoC)
CoC liegt vor, wenn die Interpretation von Daten in zwei Elementen gleich sein muss. Ein typisches Beispiel ist der Switch Case.

Robert Martin hat mal gesagt “Switch Cases are like the Sith, always two there are.” Die Implikation ist, dass case "regular" und case "childrens" in mindestens zwei Elementen auftauchen wird und die movie Business-Logik quasi zufällig verteilt wird auf Elemente.
Wir können dieses Problem lösen, indem wir movie.code und damit den Switch Case durch den polymorphen Aufruf amount() ersetzen: let thisAmount = movie.amount(); . Wir sind von CoC auf CoT gegangen.
In dem Beispiel gibt es noch weitere CoC. if(thisAmount > 25) enthält eine Magic Number, ein bekannter code smell. Welche Bedeutung steckt hinter der 25 und taucht diese vielleicht an einer anderen Stelle noch einmal auf?
An dieser Stelle ist es angebracht, die 25 durch eine benannte Konstante zu ersetzen und einen Schritt Richtung CoN zu gehen. Komplett reduzieren konnten wir CoC trotz benannter Konstante trotzdem nicht. Wir haben immer noch Zugriff auf einen primitiven Wert. An einer anderen Stelle können wir erneut ein if(thisAmount > 25) oder if(movie.code === ...) schreiben. Wir können CoC daher nur verhindern, indem movie.code kein primitiver Wert mehr ist oder indem wir diesen Getter komplett entfernen und einen Methodenaufruf daraus machen.
CoC entsteht auch bei Funktionen, die null zurückgeben oder bei Funktionen, die ihr Verhalten auf Grund der Bedeutung eines Eingabeparameters ändern. Der Parameter hat dann irgendeine semantische Bedeutung, aber sie ist nicht ersichtlich. Weil sich CoC mit der Bedeutung von Elementen beschäftigt, ist sie auch bekannt als Connascence of Meaning. Speziell bei Funktionen kann die Bedeutung durch explizite Namen klar gemacht werden, wodurch wir auf CoN reduzieren:
| Convention | Name | |
|---|---|---|
| titles(“Cornetto”); | → | titlesContaining(“Cornetto”); |
| titles(true); | → | availableTitles(); |
| titles(false); | → | rentedTitles(); |
| titles(0); | → | mostRecentRentedTitle(); |
| titles(-1); | → | leastRentedTitle(); |
| titles(null); | → | allTitles(); |
Connascence of Algorithm (CoA)
CoA entsteht, wenn zwei Elemente Daten auf dieselbe Art und Weise betrachten oder manipulieren müssen. In unserem Beispiel müssen sich sowohl Server wie Client einig sein, was ein valides Passwort ist.
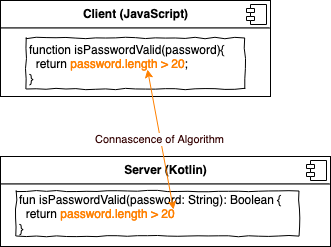
Wir könnten die Connascence der Password-Validierung reduzieren auf CoC, indem der Server dem Client die Validierung in Form eines Regex mitschickt: let validPassword = (.{19,}). Falls sich die Passwortvalidierung ändert, müssen wir jetzt nur den Server anpassen, nicht mehr den Client.
Ein anderes Beispiel für CoA sind JSON Web Tokens (JWT). Auch hier muss sie Erstellung und die Auswertung des Tokens auf Client und Serverseite gleich ablaufen.
CoA ist allerdings nicht nur auf die Validierung von Daten beschränkt. Es geht vielmehr darum, dass sich zwei Elemente einig darüber sind, welche expliziten Parameter bzw. impliziten Kontextvariablen (beides Vorbedingungen) und welche expliziten Rückgabewerte bzw. impliziten Seiteneffekte (beides Nachbedingungen) daraus entstehen. Man kennt das auch aus dem von Betrand Meyer definierten Design by Contract (DbC).
Das Element, dass isPasswordValid auf Server oder Client-Seite aufruft, garantiert die Vorbedingung, dass password nicht null ist und das Property length bereitstellt. isPasswordValid wiederum garantiert die Nachbedingung, dass bei korrekten Eingabeparametern keine Exception fliegt. Darüber hinaus wird das Ergebnis ein Boolean sein und beschreiben, ob password valide ist.
Manche Eigenschaften dieses Vertrags zwischen aufrufendem Code und aufgerufenem Code kann man mit einem Typsystem modellieren. Andere müssen von Entwicklern bedacht werden. CoA verlangt, dass wir uns diesen impliziten Vertrag bewusst machen. Jim Weirich bezeichnete CoA daher auch als Connascence of Contract.
Connascence of Position (CoP)
CoP entsteht, wenn die Reihenfolge von Elementen immer gleich sein muss. In unserem ersten Beispiel entsteht das beim Funktionsaufruf und beim Verarbeiten der Rückgabe der Funktion.
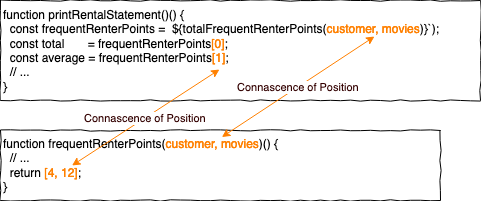
Wenn meine Programmiersprache named parameters unterstützt, kann ich CoP im Funktionsaufruf in CoN umwandeln. Alternativ kann ich ein Parameter Object einführen. Unser zweites Beispiel ist der Rückgabewert von frequentRenterPoints. Auch hier könnte es sinnvoll sein, ‘runter” auf CoT zu gehen und die Rückgabe zu einem Objekt zu machen. Wir könnten aber auch beschließen, CoP hier zuzulassen, falls die anderen beiden Connascence Regeln das zulassen.
Dynamische Formen von Connascence
Die bisher gezeigten Formen zählt man zur statischen Connascence. Sie sind durch die lexikalische Struktur der Codes vorgegeben und können in manchen Sprachen bereits zur compile time erkannt werden. Schwerer wiegende Formen der Connascence sind dynamisch und entstehen zur Laufzeit durch die Reihenfolge, in der Code ausgeführt wird.
Connascence of Execution (Order) (CoE)
CoE entsteht, wenn die Aufrufsreihenfolge relevant ist.
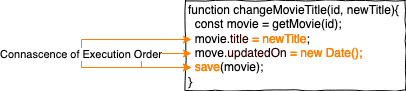
Die Korrektheit der Anwendung ist nicht gegeben, wenn save() aufgerufen wird, bevor movie.title und movie.updatedOn geändert wurde. Durch die starke Lokalität ist die Connascence hier zwar zu verkraften, wir können sie allerdings trotzdem reduzieren, indem wir save() aus der Funktion herausnehmen und changeMovie() jetzt das veränderte movie-Objekt zurückgibt: save(changeMovie(...)).
Weitere Beispiele für CoE sind State Machines, Locks auf Ressourcen oder Shared Mutable State wie Singletons.
Connascence of Timing (CoTi)
CoTi entsteht, wenn der zeitliche Ablauf Auswirkung auf unseren Code hat. In unseren Beispiel erwartet der Client, dass nach einem bestimmten timeout der Server geantwortet hat.
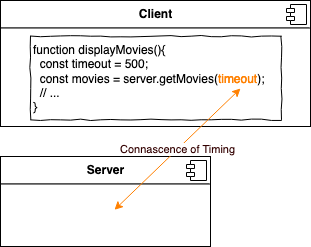
Ohne unsere grundlegende Client-/Server-Architektur zu überdenken, können wir die Connascence hier nicht reduzieren. Wir könnten aber durch Caching die unmittelbaren Auswirkungen auf den Nutzer verzögern. Leider erhöhen wir damit auf CoI (Connascence of Identity), wie wir gleich sehen werden.
Im Gegensatz zu CoE tritt CoTi nur bei nebenläufigen Elementen auf. Durch Threading kann CoTi daher auch bei einer Server-only Architektur auftreten. Die negative Auswirkung nennt man dann auch eine Race Condition.
Connascence of Value (CoV)
CoV entsteht, wenn eine Invariante (permanente Bedingung) besagt, dass sich zwei oder mehr Werte gleichzeitig ändern müssen.
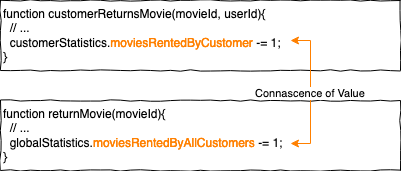
Das Problem an dieser Stelle ist, dass die Connascence zu weit entfernt ist. Wenn wir moviesRentedByCustomer sowie moviesRentedByAllCustomers in dieselbe Funktion schieben, können wir die Invariante besser beschützen.
CoV tritt bei solchen Invarianten auf, oder wenn Werte in Tests direkt gekoppelt sind an Werte, die in der zu testenden Implementierung genutzt werden. Letzteres merken wir zum Beispiel, wenn wir die Implementierung einem Refactoring unterziehen und plötzlich die Tests rot sind.
Connascence of Identity (CoI)
Die bereits erwähnte CoI ist die stärkste Form und entsteht, wenn an zwei oder mehr Stellen dasselbe Objekt referenziert sein muss.
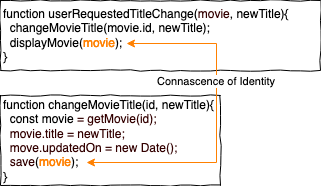
Welcher Titel wird beim Aufruf von displayMovie() anzeigt? In unserem Beispiel ist es der alte Titel, da die beiden movie-Objekte in userRequestedTitleChange() und changeMovieTitle() nicht dieselbe Identität haben. Wenn changeMovieTitle() ein movie-Objekt zurückgibt, können wir dieses an displayMovie weitergeben und CoI so vermeiden. Es wäre in diesem Beispiel auch besser, wenn userRequestedTitleChange() kein movie-Objekt erwartet, sondern direkt die movieId.
Weitere typische Szenarien für CoI sind Datenreplikationen zwischen Client und Server, wie sie auch durch Caching entstehen, oder O/R-Mapper ohne Identity Map. Diese speichern ein übergebenes Objekt in der Datenbank, generieren bei jeder Query allerdings immer ein neues Objekt mit neuer Identität.
Contranascence
Eine weitere Form der Connascene ist die Contranascence oder Connascence of Difference. Sie besagt, dass zwei Elemente sich immer unterscheiden müssen, damit die Korrektheit des Programms gegeben ist. Die Konstante GENRE_ACTION darf beispielsweise niemals den Wert 1 haben, sonst gibt es Drama.
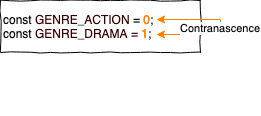
Ein weiteres Beispiel sind Namenskonflikte. In Objektive-C müssen Klassennamen im gesamten Projekt inklusive aller genutzten Frameworks und Libraries eindeutig sein. Daher müssen alle Klassen mit einem Prefix signalisieren, wo sie herkommen. Apple reserviert alle 2-Buchstaben-Prefixe dabei für sich (UIViewController, NSObject etc.). Andere Programmiersprachen nutzen stattdessen namespaces. Hier darf dann innerhalb einer Datei oder einem code block nicht zwei mal eine Methode mit demselben Namen oder derselben Signatur existieren.
Rules
Die ersten drei vorgestellten Regeln wurden von Jim Weirich aus den drei guidelines von Meilir Page-Jones abgeleitet. Für mich sind die Regeln präziser und hilfreicher als die Guidelines. Deshalb möchte ich hier die Regeln vorstellen:
Die erste Regel ist die Rule of Strength (RoS). Sie weist uns darauf hin, dass wir versuchen sollten, möglichst schwache Connascence zu erzeugen. Stärke ist danach definiert, wie schwierig die Connascence zu entdecken und danach zu refactoren ist.
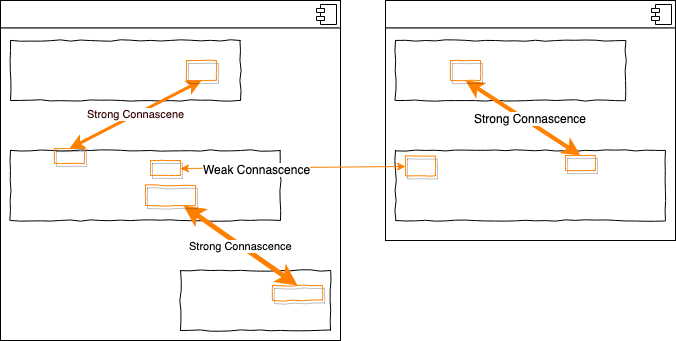
Die vorigen Beispiele haben allerdings gezeigt, dass es nicht immer möglich und sinnvoll ist, das Stärkelevel zu reduzieren. Das ist erstmal nicht schlimm, so lange wir dann die Rule of Locality (RoL) beachten. Diese besagt, dass nahe beieinander liegender Code eine stärkere Form von Connascence haben darf. Je weiter entfernt Code voneinander ist, desto schwächer sollte die Connascence sein. Umgekehrt sollten wir Code mit starker Connascence näher zusammen rücken. Diese Regel hat daher direkte Auswirkung darauf, wie wir unseren Code in Ordner und Dateien strukturieren.
Code in derselben Methode hat die höchste Lokalität, Code in der selben Datei weniger, Code im selben Ordner noch weniger, Code von einem anderen Team noch viel weniger. Das ist insofern relevant, weil die Wahrscheinlichkeit, dass zwei Teams kommunizieren, invers proportional zu der Distanz zwischen diesen Teams ist. Je weiter weg Teams voneinander sind, desto geringer sollte die Connascence daher sein. Wir können Connascence also auch auf Teams oder Unternehmen anwenden.
Die Rule of Degree (RoD) besagt, dass Elemente mit einem hohen Grad an Connascence schwieriger zu verstehen und zu ändern sind, als Elemente mit einer geringen RoD. Zwei Funktionsparameter oder Rückgabewerte kann man noch akzeptieren, speziell, wenn sie nah beieinander sind. Je mehr es werden, desto mehr fällt die RoD ins Gewicht und wir sollten ein Refactoring durchführen.
Außerdem gibt es noch die von Jim Weirich entworfene Rule of Stableness (RoS). Diese ist speziell dann sinnvoll, wenn die ersten drei Regeln nicht befolgt werden können. Wenn ein Element eine starke Form, niedrige Locality und hohen Degree hat, dann sollte es sich gar nicht bis wenig ändern.
Software-Design bewerten mit 9+(3+1)
Connascence gibt uns neun Formen:
- Name
- Type
- Convention
- Algorithm
- Position
- Execution Order
- Timing
- Value
- Identity;
und 3+1 Regeln:
- Strength
- Locality
- Degree
- Stableness.
Mit diesen Elementen können wir ein Design nicht nur bewerten, sondern bekommen auch direkt Handlungsvorschläge, wie wir es mit Refactoring verbessern können (RoD und RoS fehlen in der Abbildung, weil sie in der Prio erst später auftreten):
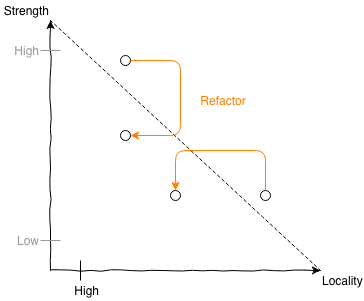
Neben den Handlungsvorschlägen gibt Connascence einem Team allerdings auch noch eine gemeinsame Sprache, um über Design zu reden – und das halte ich für den noch größeren Mehrwert. Je weniger Entscheidungen wir rein auf Erfahrung basierend fällen, desto schneller können wir als Team fruchtbare Diskussionen führen und gemeinsam lernen.
Ich glaube allerdings nicht, dass mit Connascence Code Smells und andere Praktiken ausgedient haben. Genauso verlassen sich selbst Raketenwissenschaftler bei einfachen Fragen gerne noch auf Newtons Gleichungen, statt alles gleich mit der Relativitäts- oder Quantentheorie zu erschlagen. Das gilt auch hier: Der Check auf Code Smells ist deutlich schneller zu machen, als für die involvierten Elemente die Connascence zu betrachten.
Aktiv beachte ich die Connascence daher besonders in folgenden zwei Fällen:
- Wenn ich eine API designe. Ist für den Aufrufer die Execution Order relevant, muss er interpretieren welchen Wert er zurückbekommen hat oder können bei Mehrfachaufruf Timing-Probleme entstehen? Können wir die API ändern, damit die Connascence niedriger wird?
- Wenn ich Designs bewerten möchte.
Ich komme daher nochmal auf den Codeausschnitt vom Anfang zurück und lade alle Leser ein sich zu fragen, ob das gutes oder schlechtes Design ist. Was sind die Kriterien, die diesen Code zu gutem oder schlechtem machen? Welche Formen von Connascence sind vorhanden und wie kann man durch Anwenden der Regeln diesen Code verbessern?

Über den Autor
Richard Gross
IT-Archaeologe
Richard Gross ist IT-Archaeologe und arbeitet seit 2013 für den Bereich IT-Sanierung. Seine Schwerpunkte sind hexagonale Architekturen, HATEOAS-driven APIs sowie die ausdrucksstarke und eindeutige Modellierung der Domäne als Code. Daher ist er begeistert von vielen eher jüngeren Programmiersprachen, wie Kotlin oder F#, die ihn bei der Modellierung unterstützten. Außerdem hat er auch lange Zeit das F&E Projekt CodeCharta begleitet mit dem auch Nicht-Entwickler ein Verständnis bekommen können für die Qualität ihrer Software. Privat saniert Richard auch, sein Eigenheim.
Twitter: @arghrich, Website: richargh.de
Weiterlesen
-
Techblog
KI in der Industrie erfolgreich integrieren
Effizienzsteigerung und Prozessoptimierung – der Einsatz von Künstlicher Intelligenz (KI) revolutioniert die Industrie. Firmen entdecken zunehmend, dass KI-Anwendungen nicht nur Arbeitsabläufe vereinfachen, sondern auch zu einer nachhaltigeren Betriebsführung beitragen können. In diesem Ratgeber beleuchten wir, wie Künstliche Intelligenz in der Industrie genutzt werden kann, welche Vorteile der Einsatz bietet und wie Unternehmen die Technologie sinnvoll…
-
Techblog
ChatGPT im Unternehmen erfolgreich einsetzen
Zeit sparen, Effizienz steigern. ChatGPT im Unternehmen einzusetzen kann für Mitarbeitende und Führungskräfte viele Vorteile bringen. Wer damit arbeitet, stellt fest, wie schnell und wirksam GPT-3 ist. Richtig eingesetzt, lässt sich durch ChatGPT der Arbeitsalltag in Betrieben nachhaltiger gestalten. Doch wie bei jeder Technologie, gibt es Chancen und Risiken. Welche das sind und wie Sie…

