
Von Golo Roden
Estimated reading time: 8 Minuten
DDD, Event-Sourcing und CQRS
Teil 1: Theorie und Praxis Golo Roden ist Gründer und CTO von the native web. Wir freuen uns, dass er unseren TechBlog als Gastautor bereichert. Er twittert unter @goloroden. In den vergangenen Jahren waren DDD (Domain-Driven Design), Event-Sourcing und CQRS (Command Query Responsibility Segregation) nur wenigen Entwicklern bekannt. Das ändert sich derzeit, denn die drei Konzepte finden mehr und mehr Verbreitung. Allerdings werden sie…

Teil 1: Theorie und Praxis
Golo Roden ist Gründer und CTO von the native web. Wir freuen uns, dass er unseren TechBlog als Gastautor bereichert. Er twittert unter @goloroden.
In den vergangenen Jahren waren DDD (Domain-Driven Design), Event-Sourcing und CQRS (Command Query Responsibility Segregation) nur wenigen Entwicklern bekannt. Das ändert sich derzeit, denn die drei Konzepte finden mehr und mehr Verbreitung. Allerdings werden sie häufig unterschiedslos in einen gemeinsamen Topf geworfen, obwohl sie eigentlich unabhängig voneinander sind.
Um die Unterschiede und Gemeinsamkeiten besser einordnen zu können, müssen Sie die Konzepte zunächst verstehen und eine Vorstellung von deren Kern bekommen. Am wichtigsten, aber zugleich auch am schwierigsten zu greifen, ist dabei DDD. Das liegt daran, dass sich DDD im Gegensatz zu Event-Sourcing und CQRS nicht mit Technologie befasst, sondern mit der Fachlichkeit, die jeder Anwendung zugrunde liegt.
Was ist DDD?
Domain-Driven Design ist eine Vorgehensweise zur Softwareentwicklung, die das Modellieren der fachlichen Prozesse in den Vordergrund rückt. Das Modellieren findet dabei üblicherweise in interdisziplinären Teams statt, sodass unter anderem Fachexperten, Entwickler und Designer frühzeitig miteinander kommunizieren und auf dem Weg ein gemeinsames Verständnis der Thematik entwickeln.
Zugleich erarbeiten sie auf dem Weg eine gemeinsame Sprache, die sogenannte Ubiquitous Language. Das vereinfacht die Kommunikation in den späteren Phasen der Entwicklung spürbar. Obgleich die Begriffe dieser Sprache von der modellierten Fachdomäne abhängen, folgt sie doch gewissen Regeln.
So gibt es beispielsweise Commands, die die Wünsche der Anwender repräsentieren und stets als Imperativ formuliert sind. Events hingegen sind die von der Anwendung als Reaktionen auf die Commands geschaffenen Fakten, die historisch nicht mehr veränderlich sind und deshalb in der Vergangenheitsform stehen. Die gemeinsame Logik der Commands und Events ist in den sogenannten Aggregates gekapselt.
Das Besondere an DDD ist, dass es im Gegensatz zu CRUD nicht die Daten der Anwendung in den Mittelpunkt rückt, sondern die Prozesse. Warum das wichtig ist, hat Steve Yegge sehr anschaulich in seinem Blogeintrag „Execution in the Kingdom of Nouns“ beschrieben.
Was ist Event-Sourcing?
Im Gegensatz zu DDD handelt es sich wie bereits erwähnt bei Event-Sourcing um ein technisches Konzept. Konkret beschäftigt sich Event-Sourcing mit einer speziellen Art, Daten zu speichern. Anders als in klassischen relationalen Datenbanken speichert man dabei nicht den aktuellen Zustand der Anwendung, sondern die einzelnen Veränderungen, die im Lauf der Zeit dorthin geführt haben.
Entscheidend dabei ist, dass Sie der Liste der Veränderungen ähnlich wie bei Git ausschließlich neue Einträge anfügen dürfen. Die Anweisungen UPDATE und DELETE dürfen nicht ausgeführt werden, da sie historische Daten unwiderruflich zerstören. Auf dem Weg erhalten Sie also eine kontinuierlich wachsende chronologische Liste von Veränderungen.
Selbstverständlich können Sie diese Liste im Rahmen eines sogenannten Replays wieder abspielen, um den aktuellen Zustand der Anwendung zu ermitteln. Sie können aber auch den gestrigen Zustand wiederherstellen, oder den von vor einer Woche oder vor einem Monat, oder von jedem beliebigen Zeitpunkt der Vergangenheit. Sie können außerdem auch Daten im Verlauf der Zeit vergleichen – und all das, ohne dass sie dafür dedizierte Tabellen pflegen müssten.
En passant führen Sie auf die Art außerdem ein Audit-Log und erhalten eine einfache Möglichkeit, einen Undo-/Redo-Mechanismus und vieles mehr zu implementieren.
Was ist CQRS?
CQRS ist ebenfalls ein technisches Konzept: Das Architekturmuster schlägt vor, eine Anwendung in eine Schreib- und eine Leseseite zu unterteilen, die Sie regelmäßig synchronisieren müssen. Der Vorteil davon ist, dass Sie die Schreib- und die Leseseite auf die jeweiligen Anforderungen optimieren können, beispielsweise das Sicherstellen der Integrität und Konsistenz beim Schreiben, und das effiziente Abfragen von Daten beim Lesen.
Wie Sie die Trennung konkret durchführen, lässt CQRS offen. Sie können das beispielsweise mit Hilfe zweier APIs bewerkstelligen, die im Hintergrund auf unterschiedliche Datenbanken zugreifen. Sie können aber ebenso gut nur eine API mit einer einzigen Datenbank verwenden, und die Trennung lediglich auf der Basis von Datenbankschemata durchführen.
Unabhängig von der konkreten Implementierung zieht CQRS durch die erforderliche Synchronisation jedoch stets Eventual Consistency nach sich. Das bedeutet, dass die Schreib- und die Leseseite nicht zwingend zeitgleich konsistent sind, sondern mit einem geringen zeitlichen Versatz. Für die meisten Anwendungen ist das unproblematisch, trotzdem sollte man sich der Auswirkungen bewusst sein. Gregor Hohpe hat das sehr gut in seinem Artikel Your Coffee Shop Doesn’t Use Two-Phase Commit beschrieben.
Unabhängige Konzepte
Wie eingangs bereits erwähnt sind DDD, Event-Sourcing und CQRS tatsächlich unabhängig voneinander. Jedes der drei Konzepte können Sie eigenständig verwenden, ohne den Einsatz der beiden anderen jemals erwägen zu müssen.
Sie können beispielsweise Domain-Driven Design verwenden, um eine Domäne zu modellieren, implementieren die Anwendung dann aber auf der Basis einer klassischen relationalen Datenbank und einer vielleicht nicht mehr zeitgemäßen, aber funktionstüchtigen monolithischen Code-Basis. Daher brauchen Sie hierfür weder Event-Sourcing noch CQRS.
Analog dazu können Sie Event-Sourcing verwenden, um die Rohdaten von Sensoren zu speichern, die im Rahmen einer IoT-Anwendung erzeugt werden. Da es dabei primär um das effiziente Schreiben der Daten und deren spätere Analyse geht, gibt es zunächst weder Bedarf an der Modellierung semantischer Prozesse noch am Einsatz einer Architektur, die das Optimieren der Leseseite ermöglicht. Sie benötigen also weder DDD noch CQRS.
Auch CQRS können Sie einzeln einsetzen. Dazu genügt es beispielsweise, wenn Sie in einer Anwendung zwei APIs anbieten, von denen die eine dem Ändern, die andere dem Abfragen des Zustands dient. Schon haben Sie CQRS implementiert – ganz ohne DDD und Event-Sourcing. Dass Event-Sourcing und CQRS nicht zwingend zusammen gehören, ist ausführlich im eingangs verlinkten Beitrag beschrieben.
Gemeinsam mehr erreichen
Dennoch gibt es ein verbindendes Element zwischen DDD, Event-Sourcing und CQRS, weshalb sich die drei Konzepte in der Praxis hervorragend kombinieren lassen. Die Rede ist von den Events. In Domain-Driven Design fungieren sie als fachliche und semantische Grundlage für die Modellierung. In Event-Sourcing legt bereits der Name nahe, dass es ebendiese Events sind, die es als Veränderungen zu speichern gilt. Und in CQRS dienen Events schließlich der Synchronisation von Schreib- und Leseseite.
Die folgende Abbildung stellt den Zusammenhang zwischen DDD, Event-Sourcing und CQRS an Hand des Datenflusses einer Anwendung grafisch dar:
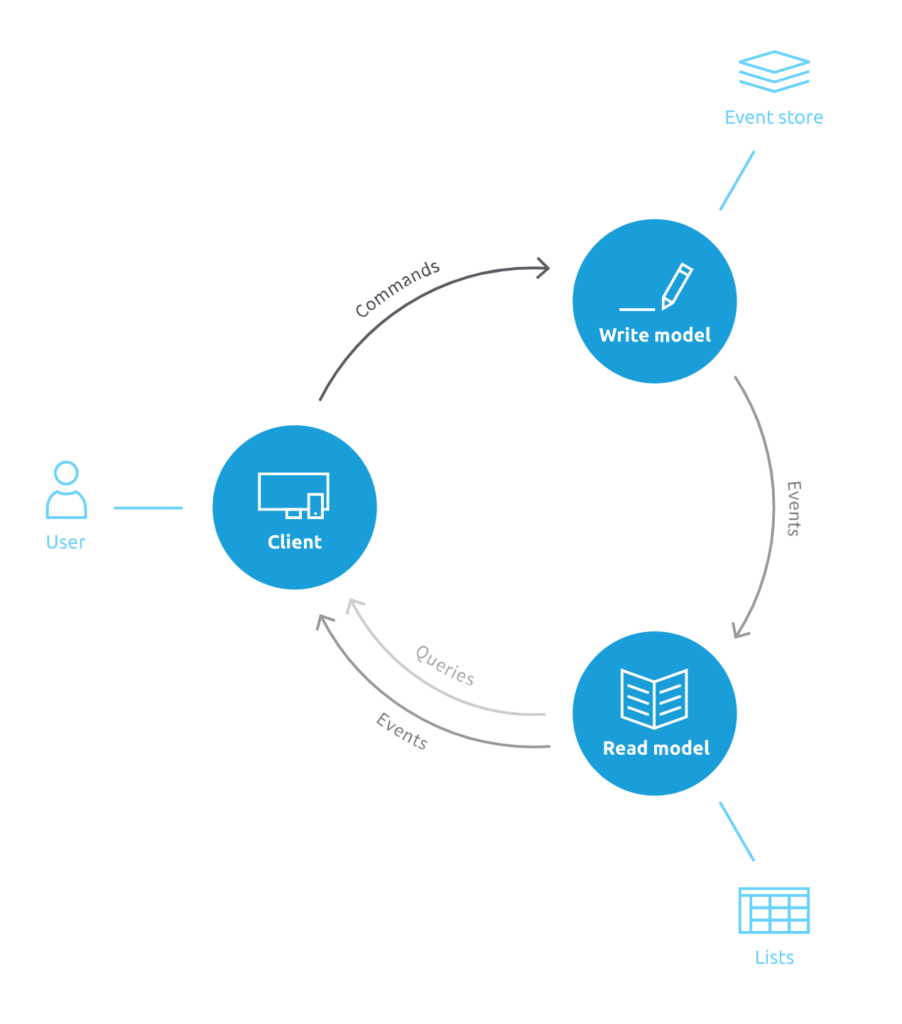
Im Write Model – also der Schreibseite der Anwendung – können Sie DDD nutzen, um eingehende Commands zu verarbeiten und diese in Events zu transformieren. Diese Events legen Sie anschließend mit Hilfe von Event-Sourcing in einer speziellen Event-Datenbank ab, dem sogenannten Event-Store. Danach werden die Events für die Synchronisation der Schreib- und der Leseseite, die in einer CQRS-Anwendung existieren, an das Read Model übertragen. Dort interpretieren Sie die Events und aktualisieren die zu lesenden Listen entsprechend Ihren Anforderungen.
Auf die Art fügen sich die drei Konzepte wie Puzzleteile zu einem großen Ganzen zusammen. Als Ergebnis erhalten Sie einen Ansatz zum Entwickeln von Anwendungen, der sich nah an der Fachlichkeit bewegt, hervorragende Analysemöglichkeiten bietet, und der sich äußerst gut skalieren lässt. Dank dem Einsatz von DDD war von Vornherein ein interdisziplinäres Team involviert, weshalb Ihnen auf dem Weg in kürzerer Zeit bessere Software gelingt.
Allerdings brauchen Sie dazu noch einen Plan, wie Sie ein derart strukturiertes System in die Praxis umsetzen. Wie das funktioniert, zeigt Ihnen der zweite Teil meiner kleinen Serie.
Über den Autor
Von Golo Roden
Weiterlesen
-
Techblog
DevOps in der Praxis: Wie Sie Zusammenarbeit neu definieren
DevOps verbindet Entwicklung und Betrieb und ermöglicht es, Software schneller, effizienter und stabiler bereitzustellen. Erfahren Sie, wie der DevOps-Lebenszyklus funktioniert, welche Tools und Methoden Sie einsetzen können und welche Vorteile dieser Ansatz für Ihre Teams und Prozesse bietet.
-
Techblog
Cloud Architekturen verstehen und optimal nutzen
Die richtige Cloud-Architektur ist der Schlüssel, um IT-Ressourcen effizient zu nutzen, Kosten zu senken und flexibel auf Veränderungen zu reagieren. Aber was genau macht eigentlich eine erfolgreiche Cloud-Architektur aus?

